MuleSoft Data Sync - Watermarking
Tips for using MuleSoft's watermarking feature.

This post will examine the MuleSoft watermarking feature as it pertains to Mule 3.x. I'm mostly going to cover some topics where I think the existing documentation is lacking, and give you a checklist you can use when you're developing your data sync solution. This way, you can save some time by avoiding some of the mistakes I made. The following are some tips you may want to follow when implementing a solution that uses watermarking.
Understand what watermarking is, understand its use cases
I don't want to spend a lot of time describing something that's already been well-said. If you're curious about what watermarking is, and when you need it, I'd recommend you start with Mariano Gonzalez's blog post.
There is one thing I want to explain in more detail. Given the following watermark configuration:
<watermark variable="lastUpdateDate" default-expression="2018-04-30T16:00:00" selector="MAX" selector-expression="#[payload.updateTimestamp]"/>
The variable attribute caused me a little confusion initially. The variable attribute is the name of the flowVar that will hold the watermark value over the course of the flow. When the poll triggers for the first time, variable is populated with whatever default-expression returns. variable is just the name of a flowVar, and can be accessed throughout the flow just like any other flowVar. After the first run, the watermark value is updated per the selector and selector-expression, or update-expression, whichever is defined. In this case, variable will be set with the biggest updatedTimestamp of all the records that were processed.
Here's a visual representation of how the watermark value can change (or not) over the course of the flow:
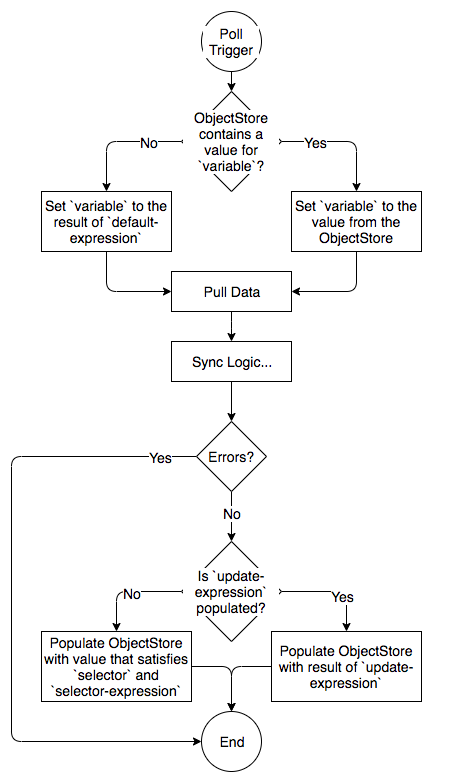
If variable is named lastedUpdatedDate, then you will have access to flowVars.lastUpdatedDate throughout the "Pull Data" and "Sync Logic..." pieces above. Where "Pull Data" represents all the logic within the inbound portion of the flow, and "Sync Logic..." represents what's contained in rest of the flow.
Understand your data source
One of the first things you'll want to do when someone asks you to provide some kind of sync solution is determine if it's even possible given the current state of their system. The key with watermarking is you need a... watermark. In other words, each record that you sync needs to have some field that you can compare against the watermark that allows you determine if you've already processed that record. This can play out in a few different ways:
- An auto-incrementing index. In this case, the watermark would be the value of the biggest index that was last processed.
- A datetime field like
LAST_UPDATED. In this case, the watermark would be the value of the most recent date that was last processed. - Any weird combination of fields that your use case might dictate.
Keep in mind that not only does your source need to have some kind of field that you can compare your watermark against, it also needs to provide a means to execute queries against that field. With databases this shouldn't be a problem. However, with RESTful APIs or web services, it could be. If you own the API, it's not a huge deal because you can modify it as needed. For example, let's say you have an API that returns something like this:
[
{
"id": 1,
"firstName": "Joshua",
"lastName": "Erney",
"instrument": "guitar"
"lastUpdated": "2018-01-01T00:00:00",
"createdAt": "2018-01-01T00:00:00"
},
{
"id": 2,
"firstName": "Nate",
"lastName": "Smith",
"instrument": "drums"
"lastUpdated": "2018-01-02T00:00:00",
"createdAt": "2018-01-02T00:00:00"
}
]
And the RAML looks like this:
/people:
get:
responses:
200:
body:
application/json:
Do you see the problem? In this case, you will certainly use the lastUpdated field to do your watermarking, but how are you going to compare the watermark to determine which records need to be synced? How are you going to prevent the application from grabbing ALL of the records, instead of just the ones your application needs? You need to be able to perform an operation that satisfies something like "give me all the records that have been created/updated since the last time I pulled data from this service." If you own the API, modify it to include a query parameter like lastUpdatedSince. When that field is provided, the API will only return fields where #[lastUpdated > lastUpdatedSince]. If you don't own the API, solutions may be more complicated, ranging from requesting the feature be added, to wrapping the API with a more friendly interface and handling the complexity under the covers.
Within "understand your data source" is also knowing if the query executed against your datasource will work for your needs. For example, I was using SQL Server recently and was using this query to get the fields needed to sync:
select * from TABLE where UPDATE_TIMESTAMP > '2018-04-30 20:54:57';
Guess what it returned me? Two records where UPDATE_TIMESTAMP was exactly '2018-04-30 20:54:57'. So my watermarking solution would keep grabbing these two records and "updating" them over and over. Turns out something like this got the job done nicely:
select * from TABLE where convert(char, UPDATE_TIMESTAMP, 20) > '2018-04-30 20:54:57';
The lesson here: make sure your data source can support what you need for watermarking, and make sure the query used to support watermarking will actually fulfill its purposes.
Understand how your connector returns data
It's important to know how your connector returns data because the watermarking feature can only work with Iterators or Iterables.
So far, I've worked with two different connectors with watermarking: The database connector, and the HTTP connector. The database connector works easily with watermarking because it returns a Java List when executing SELECT statements against a SQL database. The HTTP connector is a bit different. It returns a stream which is not Iterable. If you nest the HTTP Listener inside the poller and run the app, you'll get a helpful error like this:
Poll executing with payload of class org.glassfish.grizzly.utils.BufferInputStream but selector can only handle Iterator and Iterable objects when watermark is to be updated via selectors
You might try to get around this by doing something like this (or at least I did):
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="15" timeUnit="SECONDS"/>
<watermark variable="lastUpdateDate" default-expression="${watermark.init.timestamp}" selector="MAX" selector-expression="#[payload.lastUpdated]"/>
<processor-chain doc:name="Processor Chain">
<http:request config-ref="HTTP_Request_Configuration" path="/people" method="GET" doc:name="HTTP - Get people">
<http:request-builder>
<http:query-param paramName="updateDate" value="#[flowVars.lastUpdateDate]"/>
</http:request-builder>
</http:request>
<json:json-to-object-transformer returnClass="java.util.List" mimeType="application/java" doc:name="JSON to Object"/>
</processor-chain>
</poll>
Notice the processor-chain. However, this is invalid, and while Anypoint Studio doesn't give me any design errors, it will not compile. Your way out here is to use a flow or sub-flow, and reference that, like this:
...
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="15" timeUnit="SECONDS"/>
<watermark variable="lastUpdateDate" default-expression="${watermark.init.timestamp}" selector="MAX" selector-expression="#[payload.lastUpdated]"/>
<flow-ref name="processSub_Flow" doc:name="Http Request"/>
</poll>
...
<sub-flow name="getPeople">
<http:request config-ref="HTTP_Request_Configuration_Transactions_API" path="/transactions" method="GET" doc:name="HTTP - Get transactions">
<http:request-builder>
<http:query-param paramName="updateDate" value="#[flowVars.lastUpdateDate]"/>
</http:request-builder>
</http:request>
<json:json-to-object-transformer returnClass="java.util.List" mimeType="application/java" doc:name="JSON to Object"/>
</sub-flow>
And that should do it.
Make sure your flow is using a synchronous processing strategy
In all fairness, MuleSoft has done as much as they can to make sure you know to do this when configuring watermaking (if you don't believe me, check it out right after point 2). But impatient me didn't read this, and therfore forgot to do this, so maybe you will to. You need to be sure your flow is using a synchronous processing strategy:
<flow name="sync" processingStrategy="synchronous">
When I first started working on my data sync, I was worried about what would happen if the sync didn't finish before the next polling event triggered. Would it break? Would it process duplicate elements?
Turns out you don't need to worry about this because you're forced to use a synchronous process strategy when using the watermark feature. If you don't use a synchronous processing strategy, you'll get a nice reminder with this error:
Watermarking requires synchronous polling
So whenever you see that, just make sure the processing strategy for the flow encapsulating the poller is synchronous.
The .mule directory
The watermarking feature uses an ObjectStore to persist the watermark variable between application runs. For example, the first time you run your flow, you might grab every auto-incremented ID greater than 1 from a particular database table, because your default-expression was 1. Let's say that 1000 was the last ID processed. You stop the application. Now let's say you made some optimizations and you want to determine if they will process the first 1000 records more efficiently. You run your application, the poller executes, and nothing happens. It keeps trying to grab records with an ID greater than 1000, but there are none. So, how do you reset the default value?
I typically do this by opening my terminal, navigating to my workspace and running:
$ rm -rf .mule
This will remove the entire .mule directory and any of its sub-directories, which include your ObjectStores. ONLY DO THIS LOCALLY.
If you don't want to bomb your entire .mule directory, you can get a little more precise with this:
$ rm -rf .mule/.mule/{application_name}/objectstore
When you start your application again, it will start querying for records starting with ID 1 again.
Your final Check List
Here it is:
- Do you understand how watermarking works, and what it's used for?
- Do you understand your data source? Can it currently support watermarking?
- If your inbound connector does not return
Iterators orIterables, make sure you use a flow/sub-flow to transform the payload to the appropriate type - Is your flow using a synchronous processing strategy?
- If you're testing locally and need to reset your watermark variable, delete your
.muledirectory withrm -rf .mule. ONLY DO THIS LOCALLY